应用层协议原理 principles of network applications
网络应用体系结构(application architecture):
- 客户-服务器体系结构(client-server architecture)
server:
- always-on host
- permanent IP address
- data centers for scaling
clients:
- communicate with server
- may be intermittently connected
- may have dynamic IP addresses
- do not communicate directly with each other
- P2P体系结构(P2P architecture): peer-to-peer
no always-on server
arbitrary end systems directly communicate
peers request service from other peers, provide service in return to other peers:
self scalability – new peers bring new service capacity, as well as new service demands
自扩展性(self-scalability)
- peers are intermittently connected and change IP addresses:
complex management
进程(process)通信
process: program running within a host
- within same host, two processes communicate using inter-process communication(defined by OS)
- processes in different hosts communicate by exchanging messages
客户和服务器进程:
在一对进程之间的通信会话场景中,发起通信(即在该会话中开始时发起与其他进程的联系)的进程被标识为客户,在会话开始时等待联系的进程是服务器
client process: process that initiates communication
server process: process that waits to be contacted
aside: applications with P2P architectures have client processes & server processes
进程与计算机网络之间的接口:应用程序编程接口(Application Programming Interface, API)
套接字(socket)
process sends/receives messages to/from its socket
socket analogous to door:
- sending process shoves message out door
- sending process relies on transport infrastructure on other side of door to deliver message to socket at receiving process
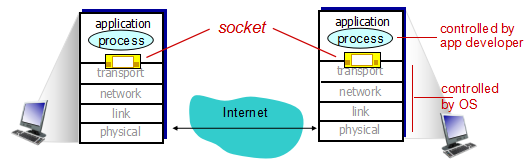
应用程序开发者对运输层的控制仅限于
- 选择运输层协议
- 设定运输层参数如最大缓存和最大报文段长度等
进程寻址:
- 主机地址:IP地址(IP address)
- 目的主机宏接受进程的标识符:端口号(port number)
- to receive messages, process must have identifier
host device has unique 32-bit IP address
Q: does IP address of host on which process runs suffice for identifying the process?
A: no, many processes can be running on same host
identifier includes both IP address and port numbers associated with process on host.
example port numbers:
- HTTP server: 80
- mail server: 25
应用程序可用运输服务
- 可靠数据传输(reliable data transfer)
- 容忍丢失的应用(loss-tolerant application)
- 吞吐量
- 带宽敏感的应用(bandwidth-sensitive application)
- 弹性应用(elastic application)
定时
安全性
data integrity
- some apps (e.g., file transfer, web transactions) require 100% reliable data transfer
- other apps (e.g., audio) can tolerate some loss
- throughput
- some apps (e.g., multimedia) require minimum amount of throughput to be “effective”
- other apps (“elastic apps”) make use of whatever throughput they get
- timing
- some apps (e.g., Internet telephony, interactive games) require low delay to be “effective”
- security
- encryption, data integrity
因特网提供的运输服务
QoS: Quantity of Service
- TCP服务:面向连接服务和可靠数据传输
TCP service:
reliable transport between sending and receiving process
flow control: sender won’t overwhelm receiver
congestion control: throttle sender when network overloaded
does not provide: timing, minimum throughput guarantee, security
connection-oriented: setup required between client and server processes
- UDP服务:不提供不必要服务的轻量级运输协议,无连接的
UDP service:
unreliable data transfer between sending and receiving process
does not provide: reliability, flow control, congestion control, timing, throughput guarantee, security, or connection setup,
安全套接字层(Secure Sockets Layer, SSL): TCP的加强版本,增加安全性服务
TCP & UDP:
- no encryption
- cleartext passwds sent into socket traverse Internet in cleartext
SSL:
- provides encrypted TCP connection
- data integrity
- end-point authentication
SSL is at app layer
- apps use SSL libraries, that “talk” to TCP
SSL socket API
- cleartext passwords sent into socket traverse Internet encrypted
应用层协议(application-layer protocol)
- 交换的报文类型
- 报文类型的语法
- 字段的语义
进程何时及如何发送报文,对报文响应的规则
types of messages exchanged,
- e.g., request, response
- message syntax:
- what fields in messages & how fields are delineated
- message semantics
- meaning of information in fields
- exchange rules for when and how processes send & respond to messages
open protocols:
- defined in RFCs
- allows for interoperability
- e.g., HTTP, SMTP
proprietary protocols:
- e.g., Skype
Telnet
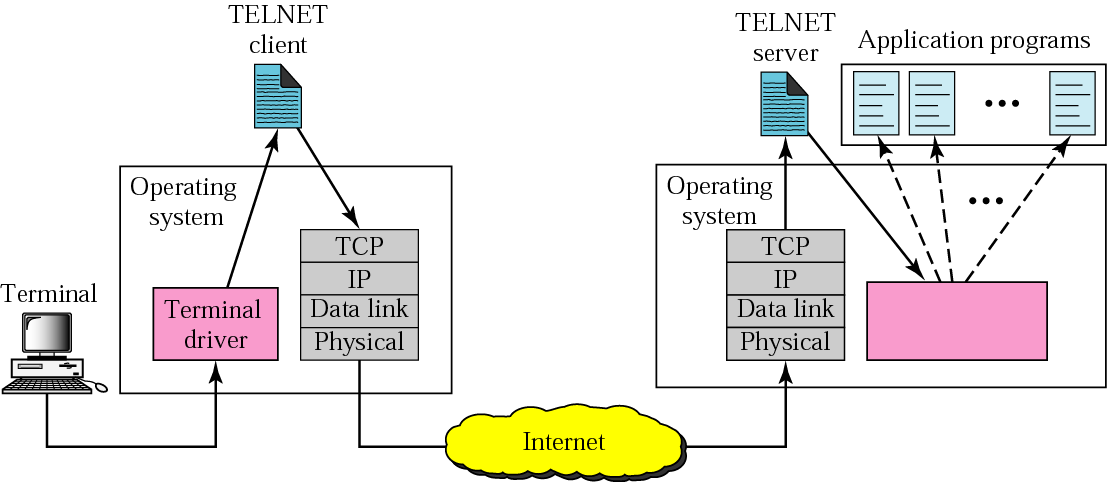
TELNET Protocol Offers three basic services:
- Defines network virtual terminal (NVT)
Basic terminal operations
standard interface
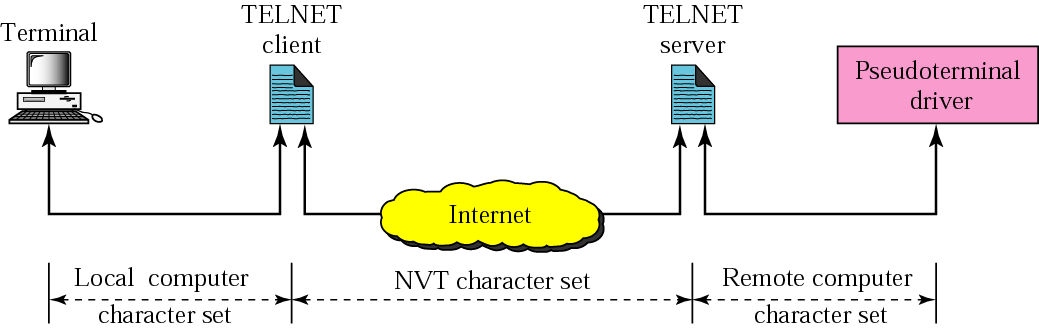
Allows client and server negotiate options
Treats both ends symmetrically
- No force on client; it can be arbitrary program
Network Virtual Terminal:
Different OS’s, different keys : Ctrl-c <–> ESC
different End of line : CR, LF, CR-LF
- TELNET defines standard
- 7 bit US ASCII
- their interpretation of control(e.g., CR-13,LF-10)
- End of line is CR-LF
- Some 8 bit octets for control functions
RLOGIN(REMOTE LOGIN)
rlogin – understands Unix environment better
- Passes some terminal parameters automatically
Trusted machines do not require password
The Rlogin process uses the TCP port 513
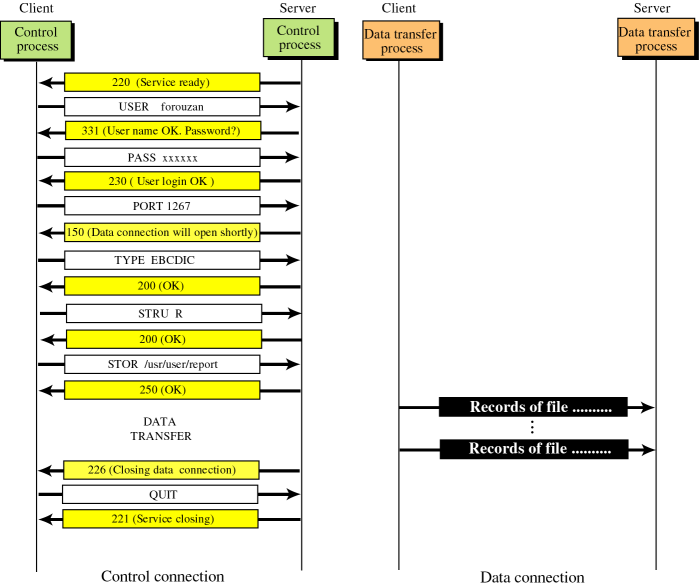
文件传输协议: FTP
FTP使用两个TCP连接传输文件
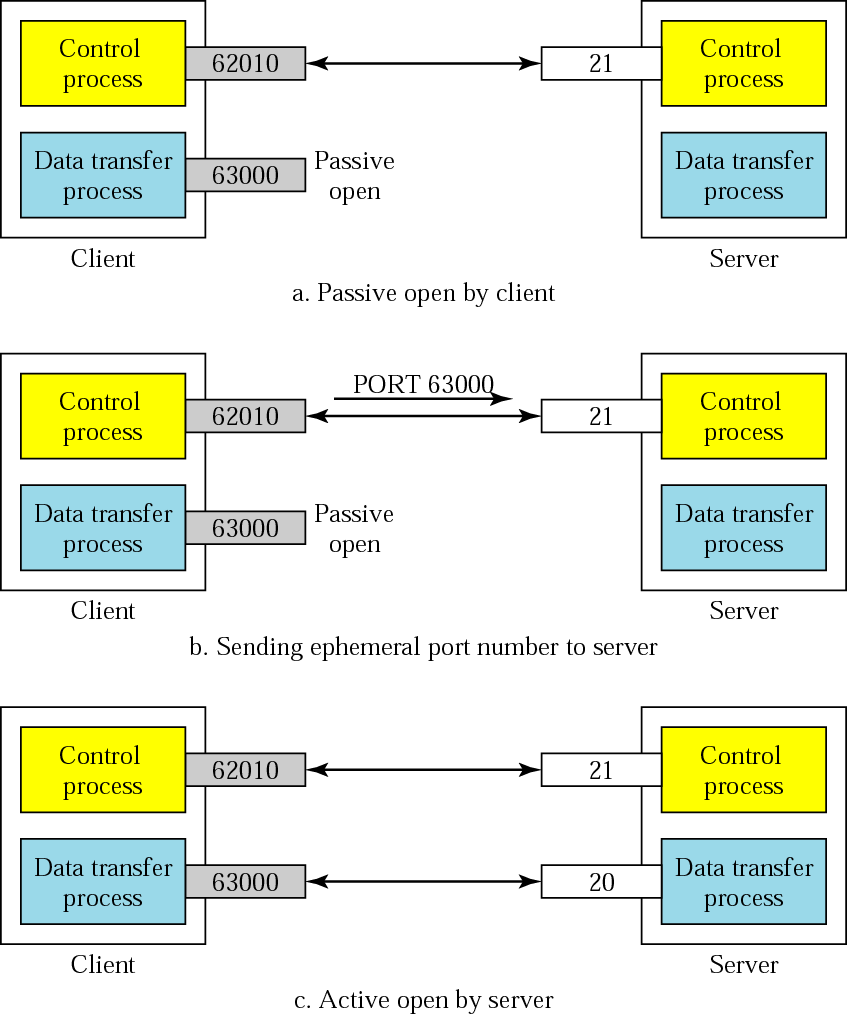
- 控制连接(control connection)
两主机之间传递控制信息:用户标识、口令、改变远程目录和’put’/‘get’等
带外传送(out-of-band)
- 数据连接(data connection)
FTP命令和回答:7比特ASCII格式在控制连接上传送,每个命令跟回车换行符(区分命令)
每个命令4个大写字母ASCII字符,部分具有可选参数 e.g. USER username、PASS password、LIST、RETR filename、STOR filename 等
回答是一个3位数字,后跟可选信息
e.g. 230 User login, OK、331 Uername OK, Password require、125 Data connection already open; transfer starting、425 Can’t open data connection、452 Error writing file 等
TFTP(Trivial File Transfer Protocol)
TFTP is intended for application with simple needs:
Simple file transfer w/o authentication
Software is much smaller than FTP
Small size of software is important
e.g., in ROM for booting diskless workstations
Uses UDP instead of TCP
- Less reliable
- Using timeout and retransmission
TFTP Reliability:
- Minimal error handling
- Most errors result in termination
Web和HTTP
- web page consists of objects
- object can be HTML file, JPEG image, Java applet, audio file,…
- web page consists of base HTML-file which includes several referenced objects
- each object is addressable by a URL
web的应用层协议:超文本传输协议(HyperText Transfer Protocol, HTTP)
HTTP: hypertext transfer protocol – Web’s application layer protocol
client/server model
- client: browser that requests, receives, (using HTTP protocol) and “displays” Web objects
- server: Web server sends (using HTTP protocol) objects in response to requests
uses TCP:
- client initiates TCP connection (creates socket) to server, port 80
- server accepts TCP connection from client
- HTTP messages (application-layer protocol messages) exchanged between browser (HTTP client) and Web server (HTTP server)
- TCP connection closed
无状态协议(stateless protocol)
HTTP is “stateless”:
server maintains no information about past client requests
protocols that maintain “state” are complex!
- past history (state) must be maintained
- if server/client crashes, their views of “state” may be inconsistent, must be reconciled
非持续连接(non-persistent connection): 每一个请求/响应对是经一个单独的TCP连接发送,如HTTP1.0
non-persistent HTTP:
- at most one object sent over TCP connection, connection then closed
- downloading multiple objects required multiple connections
suppose user enters URL: www.someSchool.edu/someDepartment/home.index (contains text, references to 10 jpeg images)
1a. HTTP client initiates TCP connection to HTTP server (process) at www.someSchool.edu on port 80
1b. HTTP server at host www.someSchool.edu waiting for TCP connection at port 80. “accepts” connection, notifying client
HTTP client sends HTTP request message (containing URL) into TCP connection socket. Message indicates that client wants object someDepartment/home.index
HTTP server receives request message, forms response message containing requested object, and sends message into its socket
HTTP server closes TCP connection.
HTTP client receives response message containing html file, displays html. Parsing html file, finds 10 referenced jpeg objects
Steps 1-5 repeated for each of 10 jpeg objects
持续连接(persistent connection): 所有的请求及其响应经相同的TCP连接发送,如HTTP1.1
persistent HTTP:
- multiple objects can be sent over single TCP connection between client, server
response time
往返时间(Round-Trip Time, RTT): 一个短分组从客户到服务器然后在返回客户的时间
RTT (definition): time for a small packet to travel from client to server and back
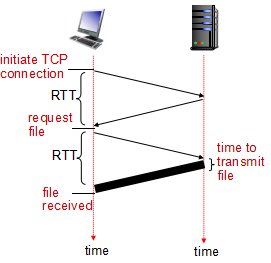
HTTP response time:
- one RTT to initiate TCP connection
- one RTT for HTTP request and first few bytes of HTTP response to return
- file transmission time
- non-persistent HTTP response time = 2RTT+ file transmission time
non-persistent HTTP issues:
- requires 2 RTTs per object
- OS overhead for each TCP connection
- browsers often open parallel TCP connections to fetch referenced objects
persistent HTTP:
- server leaves connection open after sending response
- subsequent HTTP messages between same client/server sent over open connection
- client sends requests as soon as it encounters a referenced object
- as little as one RTT for all the referenced objects
HTTP报文格式
two types of HTTP messages: request, response
HTTP request message:
- ASCII (human-readable format)
请求报文
- 请求行(request line): 方法字段、URL字段、HTTP版本字段
- 首部行(header line)(多个)
- 实体体(entity body)(POST方法才使用实体体)
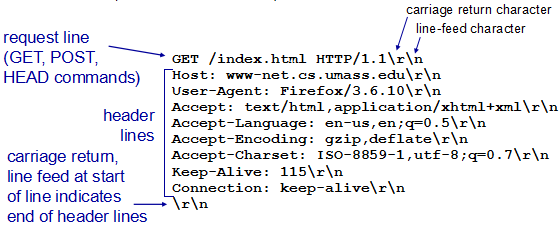
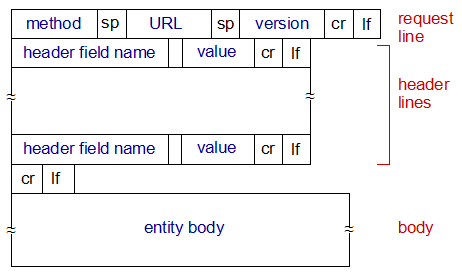
POST method:
- web page often includes form input
- input is uploaded to server in entity body
URL method:
- uses GET method
- input is uploaded in URL field of request line: www.somesite.com/animalsearch?monkeys&banana
HTTP/1.0: GET / POST / HEAD(asks server to leave requested object out of response)
HTTP/1.1:
- GET, POST, HEAD
- PUT(uploads file in entity body to path specified in URL field)
- DELETE(deletes file specified in the URL field)
响应报文
- 初始状态行(status line): 协议版本字段、状态码、相应状态信息
- 首部行(多个)
- 实体体(entity body)
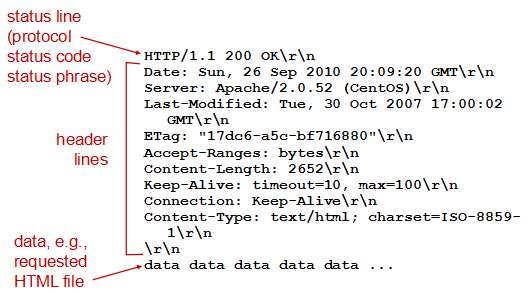
status code appears in 1st line in server-to-client response message.
some sample codes:
- 200 OK(request succeeded, requested object later in this msg)
- 301 Moved Permanently(requested object moved, new location specified later in this msg (Location:))
- 400 Bad Request(request msg not understood by server)
- 404 Not Found(requested document not found on this server)
- 505 HTTP Version Not Supported
Trying out HTTP (client side) for yourself:

用户和服务器的交互: cookie
cookie技术有四个组件:
- 在HTTP响应报文中的一个cookie首部行
- 在HTTP请求报文中的一个cookie首部行
- 在用户端系统中保留有一个cookie文件,由浏览器进行管理
- 位于Web站点的一个后端数据库
many Web sites use cookies
four components:
1) cookie header line of HTTP response message
2) cookie header line in next HTTP request message
3) cookie file kept on user’s host, managed by user’s browser
4) back-end database at Web site
example:
- Susan always access Internet from PC
- visits specific e-commerce site for first time
- when initial HTTP requests arrives at site, site creates:
- unique ID
- entry in backend database for ID
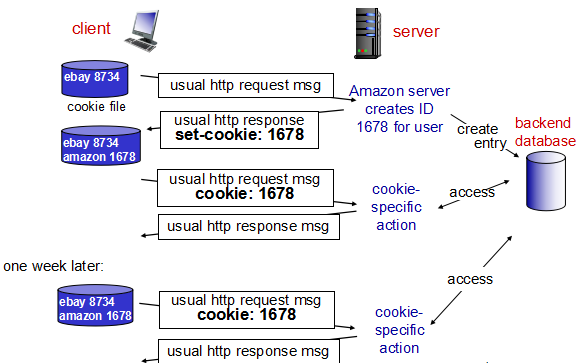
what cookies can be used for:
- authorization
- shopping carts
- recommendations
- user session state (Web e-mail)
how to keep “state”:
- protocol endpoints: maintain state at sender/receiver over multiple transactions
- cookies: http messages carry state
cookies and privacy:
- cookies permit sites to learn a lot about you
- you may supply name and e-mail to sites
Web缓存
Web缓存器(web cache)/代理服务器(proxy server): 代表初始Web服务器满足HTTP请求的网络实体
Web缓存器可以大大减少对客户请求的响应时间,特别是当客户与初始服务器之间的瓶颈带宽远低于客户与Web缓存器之间的瓶颈带宽时。
Web缓存器能够大大减少一个机构的接入链路到因特网的通信量。
goal: satisfy client request without involving origin server
user sets browser: Web accesses via cache
browser sends all HTTP requests to cache
- object in cache: cache returns object
- else cache requests object from origin server, then returns object to client
cache acts as both client and server
- server for original requesting client
- client to origin server
typically cache is installed by ISP (university, company, residential ISP)
why Web caching:
- reduce response time for client request
- reduce traffic on an institution’s access link
- Internet dense with caches: enables “poor” content providers to effectively deliver content (so too does P2P file sharing)
example:
assumptions:
- avg object size: 100K bits
- avg request rate from browsers to origin servers:15/sec
- avg data rate to browsers: 1.50 Mbps
- RTT from institutional router to any origin server: 2 sec
- access link rate: 1.54 Mbps
consequences:
- LAN utilization: 0.15%
- access link utilization = 99%
- total delay = Internet delay + access delay + LAN delay
= 2 sec + minutes + usecs
example: fatter access link
- raise access link rate to 154 Mbps
- access link utilization will change to 0.99%
- total delay will be 2sec and msecs and usecs
example: install local cache
Calculating access link utilization, delay with cache:
- suppose cache hit rate is 0.4; 40% requests satisfied at cache, 60% requests satisfied at origin
- access link utilization: 60% of requests use access link
data rate to browsers over access link = 0.6*1.50 Mbps = .9 Mbps; utilization = 0.9/1.54 = .58
total delay = 0.6 (delay from origin servers) + 0.4 (delay when satisfied at cache) = 0.6 (2.01) + 0.4 (~msecs) = ~ 1.2 secs less than with 154 Mbps link (and cheaper too!)
内容分发网络(Content Distribution Network, CDN): 地理上分散的Web缓存器
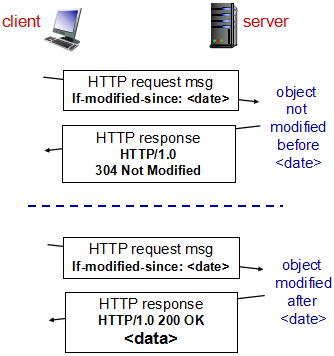
条件GET方法
conditional GET方法: HTTP协议允许缓存器证实它的对象是最新的的一种机制
请求报文使用GET方法,并且请求报文中包含一个”If-Modified-Since:”首部行
Goal: don’t send object if cache has up-to-date cached version
- no object transmission delay
- lower link utilization
cache: specify date of cached copy in HTTP request
If-modified-since:
server: response contains no object if cached copy is up-to-date:
HTTP/1.0 304 Not Modified
因特网中的电子邮件(Electronic mail)
3个主要组成部分: 用户代理(user agent)、邮件服务器(mail server)、简单邮件传输协议(Simple Mail Transfer Protocol, SMTP)
邮箱(mailbox)
User Agent
- a.k.a. “mail reader”
- composing, editing, reading mail messages; e.g., Outlook, Thunderbird, iPhone mail client
- outgoing, incoming messages stored on server
mail servers:
- mailbox contains incoming messages for user
- message queue of outgoing (to be sent) mail messages
- SMTP protocol between mail servers to send email messages
- client: sending mail server
- “server”: receiving mail server
SMTP
限制所有邮件报文的体部分职能采用7比特ASCII码表示
HTTP是一个拉协议(pull protocol): 某些人在Web服务器上装载信息,用户使用HTTP从该服务器拉取这些信息
SMTP是一个推协议(push protocol): 发送邮件服务器把文件推向接受邮件服务器
SMTP [RFC 2821]:
uses TCP to reliably transfer email message from client to server, port 25
direct transfer: sending server to receiving server
three phases of transfer
- handshaking (greeting)
- transfer of messages
- closure
- command/response interaction (like HTTP)
- commands: ASCII text
- response: status code and phrase
- messages must be in 7-bit ASCII

- SMTP uses persistent connections
- SMTP requires message (header & body) to be in 7-bit ASCII
- SMTP server uses CRLF.CRLF to determine end of message
comparison with HTTP:
- HTTP: pull vs SMTP: push
- both have ASCII command/response interaction, status codes
- HTTP: each object encapsulated in its own response message vs SMTP: multiple objects sent in multipart message
邮件报文格式(Mail message format)和MIME
From: 首部行、To: 首部行、Subject: 首部行
SMTP: protocol for exchanging email messages
RFC 822: standard for text message format:
header lines, e.g.,
- To:
- From:
- Subject:
- different from SMTP MAIL FROM, RCPT TO: commands!
Body: the “message”- ASCII characters only
邮件访问协议
不能使用SMTP取回报文,取报文是一个拉操作而SMTP协议是一个推协议
SMTP: delivery/storage to receiver’s server
mail access protocol: retrieval from server
- POP: Post Office Protocol [RFC 1939]: authorization, download
- IMAP: Internet Mail Access Protocol [RFC 1730]: more features, including manipulation of stored messages on server
- HTTP: gmail, Hotmail, Yahoo! Mail, etc.
第三版邮局协议(Post Office Protocol-Version 3, POP3)
三个阶段:
特许(authorization): 用户代理以明文形式发送用户名和口令以鉴别用户
事务处理: 用户代理取回报文,对报文做删除标记,取消报文删除标记,获取邮件的统计信息
更新: 客户发出quit命令退出POP3会话;邮件服务器删除被标记为删除的报文
邮件服务器回答: +OK正常 -ERR错误
authorization phase
client commands:
- user: declare username
- pass: password
server responses - +OK
- -ERR
transaction phase, client: - list: list message numbers
- retr: retrieve message by number
- dele: delete
- quit
more about POP3:
- POP3 “download-and-keep”: copies of messages on different clients
- POP3 is stateless across sessions
因特网邮件访问协议(Internet Mail Access Protocol, IMAP)
- keeps all messages in one place: at server
- allows user to organize messages in folders
- keeps user state across sessions: names of folders and mappings between message IDs and folder name
DNS: 因特网的目录服务
主机使用IP地址(IP address)进行标识
域名系统(Domain Name System, DNS)将主机名解析为IP地址
Internet hosts, routers:
- IP address (32 bit) - used for addressing datagrams
- “name”, e.g., www.yahoo.com - used by humans
Q: how to map between IP address and name, and vice versa ?
Domain Name System:
- distributed database implemented in hierarchy of many name servers
- application-layer protocol: hosts, name servers communicate to resolve names (address/name translation)
- note: core Internet function, implemented as application-layer protocol
- complexity at network’s “edge
DNS是一个由分层的DNS服务器(DNS Server)实现的分布式数据库
DNS是一个使得主机能够查询分布式数据库应用层协议,运行在UDP之上,使用53号端口
主机别名(host aliasing): 通常规范主机名(canonical hostname)较为复杂
邮件服务器别名(mail server aliasing)
负载分配(load distribution): 冗余的服务器(e.g. Web服务器)
DNS services:
- hostname to IP address translation
- host aliasing(canonical, alias names)
- mail server aliasing
- load distribution(replicated Web servers: many IP addresses correspond to one name)
单一DNS服务器(集中式设计)的问题(why not centralize DNS?):
单点故障(a single point of failure): DNS服务器崩溃会导致整个互联网瘫痪
通信容量(traffic volume): DNS查询体量极其大
远距离集中式数据库(distant centralized database)
维护(maintenance)
分布式设计方案(分布式层次数据库)
根DNS服务器(13个)
顶级域DNS服务器(一般域名 国家顶级域名 反向域名)
权威DNS服务器


top-level domain (TLD) servers:
- responsible for com, org, net, edu, aero, jobs, museums, and all top-level country domains, e.g.: uk, fr, ca, jp
- Network Solutions maintains servers for .com TLD
- Educause for .edu TLD
Top-Level Domain(TLD):
Generic domains:
.COM – commercial organizations
.EDU – educational institutions
.GOV – federal government institutions
.MIL – United States military
.NET – major network support centers
.ORG – other organizations
.INT – international organizations


New Top Level Domains:
| TLD | Spd/Unspd | Purpose |
| ——– | :——: | :—-: |
| .aero | spd | Air-transport industry |
| .biz | Unspd | Businesses |
| .coop | spd | Cooperatives |
| .info | Unspd | Unrestricted use |
| .museum | spd | Museums |
| .name | Unspd | For registration by individuals |
| .pro | Unspd | Accountants, lawyers, physicians, and other professionals |
Country Domains:

Inverse domain:

authoritative DNS servers:
- organization’s own DNS server(s), providing authoritative hostname to IP mappings for organization’s named hosts
- can be maintained by organization or service provider
Zones and domains:

Zone
- A primary server loads all information from the disk file;
- the secondary server loads all information from the primary server.
- When the primary downloads information from the secondary, it is called zone transfer.
Authoritative Server Configuration(example):

本地DNS服务器(local DNS server): 严格上不属于DNS层次结构,但很重要
- does not strictly belong to hierarchy
- each ISP (residential ISP, company, university) has one(also called “default name server”)
- when host makes DNS query, query is sent to its local DNS server
- has local cache of recent name-to-address translation pairs (but may be out of date!)
- acts as proxy, forwards query into hierarchy
Name Resolution:
- Resolvers use UDP (single name) or TCP (whole group of names)
- Knowing the address of the root server is sufficient
- Resolvers use recursive query.
- Servers use iterative query.
e.g.: client wants IP for www.amazon.com; 1st approximation:
- client queries root server to find com DNS server
- client queries .com DNS server to get amazon.com DNS server
- client queries amazon.com DNS server to get IP address for www.amazon.com
contacted by local name server that can not resolve name
root name server:
- contacts authoritative name server if name mapping not known
- gets mapping
- returns mapping to local name server
迭代查询(iterative query): 查询结果返回给请求者
- contacted server replies with name of server to contact
- “I don’t know this name, but ask this server”
host at cis.poly.edu wants IP address for gaia.cs.umass.edu:

递归查询(recusive query): 转发查询请求
- puts burden of name resolution on contacted name server
- heavy load at upper levels of hierarchy?

DNS Optimization:
Spatial Locality: Local computers referenced more often than remote
Temporal Locality: Same set of domains referenced repeatedly -> Caching
Caching: each entry has a time to live (TTL)
Replication: Multiple servers. Multiple roots. Ask the geographically closest server.
DNS缓存(DNS caching):
改善时延性能并减少在因特网上到处传输的DNS报文数量
once (any) name server learns mapping, it caches mapping
- cache entries timeout (disappear) after some time (TTL)
- TLD servers typically cached in local name servers, thus root name servers not often visited
cached entries may be out-of-date (best effort name-to-address translation!)
- if name host changes IP address, may not be known Internet-wide until all TTLs expire
update/notify mechanisms proposed IETF standard, RFC 2136
DNS: distributed database storing resource records (RR, 提供主机名到IP地址的映射)
RR format: (name, type, value, ttl)
type=A
- name is hostname
- value is IP address
type=NS
- name is domain (e.g., foo.com)
- value is hostname of authoritative name server for this domain
type=CNAME
- name is alias name for some “canonical” (the real) name
- www.ibm.com is really servereast.backup2.ibm.com
- value is canonical name
type=MX
- value is name of mailserver associated with name
Resource Record Types:
| Type | Meaning |
| —- | :——-: |
| A | Host Address |
| CNAME | Canonical Name (alias) |
| HINFO | CPU and O/S |
| MINFO | Mailbox Info |
| MX | Mail Exchanger |
| NS | Authoritative name server for a domain |
| PTR | Pointer to a domain name (link) |
| RP | Responsible person |
| SOA | Start of zone authority (Which part of naming hierarchy implemented) |
| TXT | Arbitrary Text |
Inserting records into DNS:
example: new startup “Network Utopia”
register name networkutopia.com at DNS registrar (e.g., Network Solutions)
- provide names, IP addresses of authoritative name server (primary and secondary)
- register inserts two RRs into .com TLD server: (networkutopia.com, NS, dns1.networkutopia.com) (dns1.networkutopia.com, A, 212.212.212.1)
- create authoritative server type A record for www.networkuptopia.com; type MX record for networkutopia.com
DNS报文: DNS查询和回答报文(query and reply both with same message format
)

message header:
dentification: 16 bit # for query, reply to query uses same #
flags:
- query or reply
- recursion desired
- recursion available
- reply is authoritative


Domain names stored as series of labels
- 1 octet length (n) (top two bits of length are 00)
- n octet label
- Zero length marks end of name
Attacking DNS
DDoS attacks
bombard root servers with traffic
- not successful to date
- traffic filtering
- local DNS servers cache IPs of TLD servers, allowing root server bypass
bombard TLD servers
- potentially more dangerous
redirect attacks
man-in-middle
- Intercept queries
DNS poisoning
- Send bogus relies to DNS server, which caches
exploit DNS for DDoS
send queries with spoofed source address: target IP
requires amplification
P2P应用
Objectives of P2P:
- Share the resources (storage and bandwidth) of individual clients
- to improve scalability/ robustness
- Bypass DNS to find clients with resources! examples: instant messaging, skype
Pure P2P architecture
- no always-on server
- arbitrary end systems directly communicate
- peers are intermittently connected and change IP addresses
- 40-70% of total traffic in many networks
P2P Examples:
- File Sharing: BitTorrent, LimeWire
- Streaming: PPLive, PPStream, Zatto, …
- Research systems
- Collaborative computing:
- SETI@Home project
- Human genome mapping
- Intel NetBatch: 10,000 computers in 25 worldwide sites for simulations
File distribution: client-server vs P2P:
how much time to distribute file (size F) from one server to N peers
peer upload/download capacity is limited resource
client-server:

server transmission: must sequentially send (upload) N file copies:
- time to send one copy: $F/u_s$
- time to send N copies: $NF/u_s$
client: each client must download file copy
- $d_{min}$ = min client download rate
- min client download time: $F/d_{min}$
time to distribute F to N clients using client-server approach(increases linearly in N):
$D_{c-s}$ > max{$NF/us, F/d{min}$}
P2P:
server transmission: must upload at least one copy
- time to send one copy: $F/u_s$
client: each client must download file copy
- min client download time: $F/d_{min}$
time to distribute F to N clients using P2P approach(increases linearly in N, but so does this, as each peer brings service capacity):
$D_{P2P}$ > max{$F/us, F/d{min}, NF/(u_s + \sum u_i)$}

Napster(Centralized Database)
Program for sharing music over the Internet
Application-level, client-server protocol over TCP
A centralized index system that maps files (songs) to machines that are alive and with files
Steps:
- Connect to Napster server
- Upload your list of files (push) to server
- Give server keywords to search the full list
- Select “best” of hosts with answers
Napster Architecture

Napster Publish

Napster Search

Summary of features: a hybrid design
- control: client-server (aka special DNS) for files
- data: peer to peer
Advantages: simplicity, easy to implement sophisticated search engines on top of the index system
Disadvantages:
- application specific (compared with DNS)
- lack of robustness, scalability: central search server single point of bottleneck/failure
- easy to sue !
BitTorrent
- A P2P file sharing protocol
- Created by Bram Cohen in 2004
A peer can download pieces concurrently from multiple locations
A global central index server is replaced by one tracker per file (called a swarm), reduces centralization; but needs other means to locate trackers
The bandwidth scalability management technique is more interesting
torrent(洪流): 参与一个特定文件分发的所有对等方(peer)的集合
追踪器(tracer)
Metadata File Structure: Meta info contains information necessary to contact the tracker and describes the files in the torrent
- announce URL of tracker
- file name
- file length
- piece length (typically 256KB)
- SHA-1 hashes of pieces for verification
- also creation date, comment, creator, …
Tracker Protocol:
Communicates with clients via HTTP/HTTPS
Client GET request
- info_hash: uniquely identifies the file
- peer_id: chosen by and uniquely identifies the client
- client IP and port
- numwant: how many peers to return (defaults to 50)
- stats: e.g., bytes uploaded, downloaded
Tracker GET response
- interval: how often to contact the tracker
- list of peers, containing peer id, IP and port
- stats
Robustness: A swarming protocol
- Peers exchange info about other peers in the system
- Peers exchange piece availability and request blocks from peers
块(chunk)

Peer Protocol:
Over TCP
Unchoke: indicate if A allows B to download
Interest/request: indicate which block to send from B to A
incentive
- Periodically (typically every 10 seconds) calculate data-receiving rates from all peers
- Upload to (unchoke) the fastest
- constant number (4) of unchoking slots
- partition upload bw equally among unchoked
- commonly referred to as “tit-for-tat” strategy(一报还一报)
Optimistic Unchoking
- Periodically select a peer at random and upload to it
- typically every 3 unchoking rounds (30 seconds)
- Multi-purpose mechanism
- allow bootstrapping of new clients
- continuously look for the fastest peers (exploitation vs exploration)
Block Availability
- Request (local) rarest first(最稀缺优先)
- achieves the fastest replication of rare pieces
- obtain something of value
Revisions
- When downloading starts (first 4 pieces): choose at random and request them from the peers
- get pieces as quickly as possible
- obtain something to offer to others
- Endgame mode
- defense against the “last-block problem”: cannot finish because missing a few last pieces
- send requests for missing sub-pieces to all peers in our peer list
- send cancel messages upon receipt of a sub-piece
Summary
- Very widely used
- mainline: written in Python
- Azureus and μTorrent: the most popular
- Other popular clients: ABC, BitComet, BitLord, BitTornado, Opera browser
Many explorations, e.g.,
- BitThief
- BitTyrant
Better understanding is needed
Gnutella
文件共享网络
Decentralized Flooding: Gnutella
- On startup, client contacts other servents (server + client) in network
- to form interconnection/peering relationships
- servent interconnection used to forward control (queries, hits, etc)
How to find a resource record: decentralized flooding
- send requests to neighbors
- neighbors recursively forward the requests
Each node forwards the query to its neighbors other than the one who forwards it the query
Each node should keep track of forwarded queries to avoid loop:
- nodes keep state (which will time out—soft state)
- carry the state in the query, i.e. carry a list of visited nodes



Basic message header: Unique ID, TTL, Hops
Message types:
- Ping : probes network for other servents
Pong : response to ping, contains IP addr, # of files, etc.
Query : search criteria + speed requirement of servent
QueryHit : successful response to Query, contains addr + port to transfer from, speed of servent, etc.
Ping, Queries are flooded
- QueryHit, Pong: reverse path of previous message
Advantages: totally decentralized, highly robust
Disadvantages:
not scalable; the entire network can be swamped with flood requests: especially hard on slow clients; at some point broadcast traffic on Gnutella exceeded 56 kbps
to alleviate this problem, each request has a TTL to limit the scope
each query has an initial TTL, and each node forwarding it reduces it by one; if TTL reaches 0, the query is dropped (consequence?)
Flooding: FastTrack (aka Kazaa)
Modifies the Gnutella protocol into two-level hierarchy
- Supernodes
- Nodes that have better connection to Internet
- Act as temporary indexing servers for other nodes
- Help improve the stability of the network
Standard nodes
- Help improve the stability of the network
- Connect to supernodes and report list of files
Search - Broadcast (Gnutella-style) search across supernodes
Disadvantages
Kept a centralized registration -> prone to law suits
分布式散列表(Distributed Hash Table, DHT)
DHT Overview
Abstraction: a distributed “hash-table” (DHT) data structure
- put(key, value) and get(key) -> value
- DHT imposes no structure/meaning on keys
- one can build complex data structures using DHT

Implementation:
- nodes in system form an interconnection network: ring, zone, tree, hypercube, butterfly network, …
DHT Applications
- File sharing and backup [CFS, Ivy, OceanStore, PAST, Pastiche …]
- Web cache and replica [Squirrel, Croquet Media Player]
- Censor-resistant stores [Eternity]
- DB query and indexing [PIER, Place Lab, VPN Index]
- Event notification [Scribe]
- Naming systems [ChordDNS, Twine, INS, HIP]
- Communication primitives [I3, …]
- Host mobility [DTN Tetherless Architecture]





Key Issues in Understanding a DHT Design:
How does the design map keys to internal representation (typically a metric space)?
Which space is a node responsible?
How are the nodes linked?
e.g. …
Content Addressable Network(CAN)
Abstraction
- map a key to a “point” in a multi-dimensional Cartesian space
- a node “owns” a zone in the overall space
- route from one “point” to another
CAN Example: Two Dimensional Space
Space divided among nodes
Each node covers either a square or a rectangular area of ratios 1:2 or 2:1





CAN Insert Example:
node I::insert(K,V)

(1) a = hx(K)
b = hy(K)

(2) route(K,V) -> (a,b)

Routing:
- A node maintains state only for its immediate neighboring nodes
- Forward to neighbor which is closest to the target point
- a type of greedy, local routing scheme

- a type of greedy, local routing scheme
(3) (K,V) is stored at (a,b)
CAN Retrieve Example:
node J::retrieve(K)

(1) a = hx(K)
b = hy(K)
(2) route “retrieve(K)” to (a,b)

CAN Insert: Join



CAN Evaluations
Guarantee to find an item if in the network
Load balancing
- hashing achieves some load balancing
- overloaded node replicates popular entries at neighbors
Scalability
- for a uniform (regularly) partitioned space with n nodes and d dimensions
- storage:
- per node, number of neighbors is 2d
- a fixed d can scale the network without increasing per-node state
- routing
- average routing path is $(dn^{1/d})/3$ hops (due to Manhattan distance routing, expected hops in each dimension is dimension length * 1/3)
Chord: search by routing/consistent hashing
Space is a ring
Consistent hashing: m bit identifier space for both keys and nodes
- key identifier = SHA-1(key), where SHA-1() is a popular hash function:
- Key=“Matrix3” -> ID=60
- node identifier = SHA-1(IP address)
- IP=“198.10.10.1” -> ID=123
Chord: Storage using a Ring
- A key is stored at its successor: node with next higher or equal ID

how to Search(One Extreme)
- Every node knows of every other node
- Routing tables are large O(N)
- Lookups are fast O(1)

- Lookups are fast O(1)
how to Search(the Other Extreme)
- Every node knows its successor in the ring
- Routing tables are small O(1)
- Lookups are slow O(N)

- Lookups are slow O(N)
Chord Solution: “finger tables”
- Node K knows the node that is maintaining K + 2i,
- increase distance exponentially

Joining the Ring
- use a contact node to obtain info
- transfer keys from successor node to new node
- updating fingers of existing nodes

DHT: Chord Node Join
- Assume an identifier space [0..8]
Node n1 joins

Node n2 joins

Node n6 joins

Node n0 joined

DHT: Chord Insert Items
- Nodes: n1, n2, n0, n6
- Items: f7, f1
Upon receiving a query for item id, a node:
- checks whether stores the item locally
- if not, forwards the query to the largest node in its successor table that does not exceed id

Chord/CAN Summary
- Each node “owns” some portion of the key-space
- in CAN, it is a multi-dimensional “zone”
- in Chord, it is the key-id-space between two nodes in 1-D ring
- Files and nodes are assigned random locations in key-space
- provides some load balancing
- probabilistically equal division of keys to nodes
- Routing/search is local (distributed) and greedy
- node X does not know of a path to a key Z
- but if it appears that node Y is the closest to Z among all of the nodes known to X
- so route to Y
video streaming and content distribution networks (CDNs)(流式视频和内容分发网络)
Multimedia: video
- video: sequence of images displayed at constant rate
- e.g., 24 images/sec
- digital image: array of pixels
- each pixel represented by bits
- coding: use redundancy within and between images to decrease # bits used to encode image
- spatial (within image)
- spatial coding example: instead of sending N values of same color, send only two values: color value and number of repeated values (N)
- temporal (from one image to next)
- temporal coding example: instead of sending complete frame at i+1, send only differences from frame i
CBR: (constant bit rate): video encoding rate fixed
- VBR: (variable bit rate): video encoding rate changes as amount of spatial, temporal coding changes
- examples:
- MPEG 1 (CD-ROM) 1.5 Mbps
- MPEG2 (DVD) 3-6 Mbps
- MPEG4 (often used in Internet, < 1 Mbps)
Streaming stored video(流式存储视频)
- simple scenario: video server(stored video) -> Internet -> client
- challenge: heterogeneity
- different users have different capabilities (e.g., wired versus mobile; bandwidth rich versus bandwidth poor)
Streaming multimedia: DASH(Dynamic Adaptive Streaming over HTTP)
server:
- divides video file into multiple chunks
- each chunk stored, encoded at different rates
- manifest file(文件清单): provides URLs for different chunks
client:
- periodically measures server-to-client bandwidth
- consulting manifest, requests one chunk at a time
- chooses maximum coding rate sustainable given current bandwidth
- can choose different coding rates at different points in time (depending on available bandwidth at time)
“intelligence” at client: client determines
- when to request chunk (so that buffer starvation, or overflow does not occur)
- what encoding rate to request (higher quality when more bandwidth available)
- where to request chunk (can request from URL server that is “close” to client or has high available bandwidth)
Content distribution networks(CDN, 内容分发网络)
video traffic: major consumer of Internet bandwidth
challenge: how to stream content (selected from millions of videos) to hundreds of thousands of simultaneous users?
option 1: single, large “mega-server”
- single point of failure
- point of network congestion
- long path to distant clients
- multiple copies of video sent over outgoing link
quite simply: this solution doesn’t scale
option 2: store/serve multiple copies of videos at multiple geographically distributed sites (CDN)
- enter deep: push CDN servers deep into many access networks
- close to users
- used by Akamai, 1700 locations
- bring home: smaller number (10’s) of larger clusters in POPs near (but not within) access networks
- used by Limelight
CDN: stores copies of content at CDN nodes
- e.g. Netflix stores copies of MadMen
subscriber requests content from CDN
- directed to nearby copy, retrieves content
- may choose different copy if network path congested
OTT(over the top) challenges: coping with a congested Internet
- from which CDN node to retrieve content?
- viewer behavior in presence of congestion?
- what content to place in which CDN node?

Caching
- explicit(明确的)
- transparent (hijacking connections)
Replication - server farms(服务器群)
- geographically dispersed(分散)(CDN)
Traditional: Performance
- move content closer to the clients
- avoid server bottlenecks
New: DDoS Protection - dissipate attack over massive resources
- multiplicatively raise level of resources needed to attack
Denial of Service Attacks (DoS)

Distributed DoS (DDoS)

Redirection Overlay

Techniques
DNS
- one name maps onto many addresses
- works for both servers and reverse proxies
HTTP - requires an extra round trip
Router - one address, select a server (reverse proxy)
- content-based routing (near client)
URL Rewriting - embedded links
Ridirection
Hashing Schemes: Modulo
- Easy to compute
- Evenly distributed
- Good for fixed number of servers
- Many mapping changes after a single server change

Consistent Hashing (CHash)
- Hash server, then URL
- Closest match
- Only local mapping changes after adding or removing servers
- Used by State-of-the-art CDNs

Highest Random Weight (HRW)
- Hash(url, svrAddr)
- Deterministic order of access set of servers
- Different order for different URLs
- Load evenly distributed after server changes

Redirection Strategies
- Random (Rand)
- Requests randomly sent to cooperating servers
- Baseline case, no pathological behavior
Replicated Consistent Hashing (R-CHash)
- Each URL hashed to a fixed # of server replicas
- For each request, randomly select one replica
Replicated Highest Random Weight (R-HRW)
- Similar to R-CHash, but use HRW hashing
- Less likely two URLs have same set of replicas
Coarse(粗略) Dynamic Replication (CDR)
- Using HRW hashing to generate ordered server list
- Walk through server list to find a lightly loaded one
- Coarse grained server load information
Fine Dynamic Replication (FDR)
- Bookkeeping min # of replicas of URL (popularity)
- Let more popular URL use more replicas
- Keep less popular URL from extra replication
Replication
Why Replicate?
- Performance
- keep copy close to remote users
- caching is a special case
Survive Failures
- availability: provide service during temporary failure
- fault tolerance: provide service despite catastrophic failure
Fault Models
- Crashed
- failed device doesn’t do anything (i.e., fails silently)
- Fail-Stop
- failed device tells you that it has failed
- Byzantine(拜占庭将军问题,Byzantine Generals Problem)
- failed device can do anything
- adversary
- playing a game against an evil opponent
- opponent knows what you’re doing and tries to fool you
- usually some limit on opponent’s actions (e.g. at most k failures)
拜占庭将军问题 (Byzantine Generals Problem),是由莱斯利兰伯特提出的点对点通信中的基本问题。 在分布式计算上,不同的计算机透过讯息交换,尝试达成共识;但有时候,系统上协调计算机 (Coordinator / Commander) 或成员计算机 (Member / Lieutanent) 可能因系统错误并交换错的讯息,导致影响最终的系统一致性。拜占庭将军问题就根据错误计算机的数量,寻找可能的解决办法 (但无法找到一个绝对的答案,只可以用来验证一个机制的有效程度)。
Synchrony
- Assumptions concerning boundedness of component execution or network transmissions
- Synchronous
- always performs function in a finite & known time bound
- Asynchronous
- no such bound
- Famous Result: A group of processes cannot agree on a value in an asynchronous system given a single crash failure
Network Partitions
Can’t tell the difference between a crashed process and a process that’s inaccessible due to a network failure.
Network Partition: network failure that cuts processes into two or more groups
- full communication within each group
- no communication between groups
- danger: each group thinks everyone else is dead
Mirroring
- Goal: service up to K failures
- Approach: keep K+1 copies of everything
- Clients do operations on “primary” copy
- Primary makes sure other copies do operations too
- Advantage: simple
- Disadvantages:
- do every operation K times
- use K times more storage than necessary
Mirroring Details
Optimization: contact one replica to read
What if a replica fails?
- get up-to-date data from primary after recovering
What if primary fails?
- elect a new primary
Election Problem
When algorithm terminates, all non-failed processes agree on which replica is the primary
Algorithm works despite arbitrary failures and recoveries during the election
If there are no more failures and recoveries, the algorithm must eventually terminate
Bully Algorithm
- Use fixed “pecking order” among processes
- e.g., use network addresses
Idea: choose the “biggest” non-failed machine as primary
Correctness proof is difficult
Bully Algorithm Details
- Process starts an election whenever it recovers or whenever primary has failed
- how to know primary has failed?(一段时间无响应)
To start an election, send election messages to all machines bigger than yourself
- if somebody responds with an ACK, give up
- if nobody ACKs, declare yourself the primary
On receiving election message, reply with ACK and start an election yourself (unless in progress)
Quorums
- Quorum(法人): a set of server machines
- Define what constitutes a “read quorum” and a “write quorum”
- To write
- acquire locks on all members of some write quorum
- do writes on all locked servers
- release locks
To read: similar, but use read quorum
Correctness requirements
- any two write quorums must share a member
- any read quorum and any write quorum must share a member (read quorums need not overlap(覆盖))
Locking ensures that
- at most one write happening at a time
- never have a write and a read happening at the same time
Defining Quorums
Many alternatives
Example
- write quorum must contain all replicas
- read quorum may contain any one replica
- Consequence
- writes are slow, reads are fast
- can write only if all replicas are available
- can read if any one replica is available
Example: Majority Quorum
- write quorum: any set with more than half the replicas
- read quorum: any set with more than half the replicas
- Consequences
- modest(适度) performance for read and write
- can proceed(进行) as long as more than half the replicas are available
Quorums & Version Numbers
- Write operation writes only a subset of the servers
- some servers are out-of-date
Remedy(纠正方法)
- put version number stamp on each item in each replica
- when acquiring locks, get current version number from each replica
- quorum overlap rules ensure that one member of your quorum has the latest version
- When reading, get the data from the latest version number in your quorum
- When writing, set version number of all replicas you wrote equal to 1 + (max version number in your quorum beforehand)
- Guarantees correctness even if no recovery action is taken when replica recovers from a crash
Quorums and Partitions
- One group has a write quorum (and thus usually a read quorum);
- that group can do anything
- other groups are frozen
- No group has a write quorum, but some groups have a read quorum
- some groups can read
- no groups can write
- No group contains any quorum
- everyone is frozen
socket programming with UDP and TCP
What is “socket”
A socket is a virtual connection between two applications
Using a socket, two processes can communicate with each other
The socket is the major communication tool for Internet applications
A socket is bi-directional (full-duplex) transmission
A socket can be created dynamically
Socket as a virtual connection between two processes

Socket as a client/server model

Port: a logical connecting point at the transport-layer protocol.


Socket programming
Two socket types for two transport services:
- UDP: unreliable datagram
- TCP: reliable, byte stream-oriented
Application Example:
- client reads a line of characters (data) from its keyboard and sends data to server
- server receives the data and converts characters to uppercase
- server sends modified data to client
- client receives modified data and displays line on its screen
Socket programming with TCP
- client must contact server
- server process must first be running
- server must have created socket (door) that welcomes client’s contact
client contacts server by:
- Creating TCP socket, specifying IP address, port number of server process
- when client creates socket: client TCP establishes connection to server TCP
- when contacted by client, server TCP creates new socket for server process to communicate with that particular client
- allows server to talk with multiple clients
- source port numbers used to distinguish clients
application viewpoint:
TCP provides reliable, in-order, byte-stream transfer (“pipe”) between client and server
Client/Server Process Organization


Unix Socket Programming Technical Details
Unix TCP server
(1) create socket:
socket_id = socket (AF_INET, SOCK_STREM, DEFAULT_PROTOCOL);
(2) bind socket:
bind (socket_id, server_addr, server_len);
(3) listen to socket:
listen (socket_id, number_of_connection);
(4) accept a connection:
accept (socket_id, &client_addr, &client_len);
(5) read (receive) data:
read (socket_id, buffer, buffer_len);
(6) write (send) data:
write (socket_id, buffer, buffer_len);
(7) close socket:
close(socket_id);Unix TCP client
(1) create socket: same as server
socket_id = socket (AF_INET, SOCK_STREM, DEFAULT_PROTOCOL);
(2) connect socket:
connect (socket_id, serverINETaddress, server_len);
(3) write (send) data:
write (socket_id, buffer, buffer_len);
(4) read (receive) data:
read (socket_id, buffer, buffer_len);
(5) close socket: same as server
close(socket_id);
Step 1: socket(…) call
It declares a socket to be used.
Prepare data structure to manage socket
OS is responsible for this
Step 2: bind(…) call
It connects a process to a specific port
Port = A logical connecting point at a host for two communicating processes using socket
Port Numbers:
0~1023: System Reserved
Port 21: FTP
Port 23: telnet
Port 80: HTTP
1024 and above: available to users
Step 3: listen(…) call
listen() system call: prepare memory buffer for incoming connections
listen (socket_id, number_of_connection) -> We need to specify how many connection requests should be held in the buffer when SERVER is busy (can’t accept a request).
Step 4 - Part 1: accept(…) call
The server process accepts a request from a client
accept() function is a blocking function
Step 4 - Part 2: accept(…) call
The accept(_) call returns another port number and establish another connection

Step 5: read( ) and write( ) call
The server and client communicate using the second socket

Step 6: close ( ) call
Close the second socket and leave the first socket for next client
Step 7: Go back to accept(…) call
The server process goes back to the accept call
Winsock Programming Technical Details
- Initialize Winsock
Step 1: Define your socket
Step 2: Initialize your socket
Step 3: Start using it
|
|
socket ( ) function : Returns socket ID on success
unsigned int socket_id = socket (AF_INET, SOCK_STREAM, 0);
bind ( ) function : Return code (< 0 if error)
int status = bind (socket_id, (struct sockaddr_in *) my_addr, sizeof(my_addr));
- The sockaddr_in structure to specify port # and IP address of this machine (server machine)
- The “sock_addr” structure
Step 1: You instantiate the structure
Step 2: Fill up the components
|
|
listen ( ) function : Return code (< 0 if error)
int status = listen (socket_id, 3);
- The size of the connection request buffer(3)
accept ( ) function : duplicated socket ID (< 0 if error)
unsingned int child_sock = accept (socket_id, (struct sockaddr_in *) client_addr, sizeof (client_addr);
recv ( ) function : On success, the number of bytes received; Return code (< 0 if error)
int status = recv (child_sock, in_buffer, MAX_BUFFER_SIZE, 0);
- The input (receive) buffer as a character string
- Example: char in_buffer [MAX_BUFFER]
send ( ) function : On success, the number of bytes actually sent; Return code (< 0 if error)
int status = send (child_sock, out_buffer, MAX_BUFFER_SIZE, 0);
closesocket ( ) function : Return code (< 0 if error)
int status = closesocket (child_sock);
- Clear winsock
After you call “closesocket” function but before your program is terminated
|
|
How to specify your destination in socket?
- Each destination for a socket connection is determined by < IP address + Port# >
sockaddr_in structure is used to define your destination
- The sockaddr_in structure is defined in C/C++ struct
- The sockaddr_in structure is defined in windows.h header file
|
|
|
|
How can I set the IP address and the port number of my destination?
- STEP #1: Instantiate a sockaddr_in structure:
- STEP #2: Set your destination IP address:
- Case 1: by “32-bit IP address”: server_address.sin_addr.s_addr = inet_addr(“146.163.147.59”);
- Case 2: by a host name: server_address.sin_addr.s_addr = inet_aton(“cougar.siue.edu”);
- Case 3: by a system-defined parameter: server_address.sin_addr.s_addr = htonl(INADDR_ANY);
- STEP #3: Set your destination port number: server_address.sin_port = htons(80);
Python Programming Technical Details
Python TCPClient:
Python TCPServer:
Socket programming with UDP
- UDP: no “connection” between client & server
- no handshaking before sending data
- sender explicitly attaches IP destination address and port # to each packet
- receiver extracts sender IP address and port# from received packet
- UDP: transmitted data may be lost or received out-of-order
- Application viewpoint: UDP provides unreliable transfer of groups of bytes (“datagrams”) between client and server
Client/server socket interaction: UDP

Python UDPClient
|
|